| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 파이썬
- 전산유체역학
- 업무
- 구글시트
- google sheet
- 유체역학
- regex
- 업무노가다
- hydrocylcone
- 후처리 프로그램
- 자동화
- 정규표현식
- 행 삽입
- Excel
- 업무자동화
- 셀 배경색
- Meshing
- 모니터링값
- pdf annotation
- CFD
- python
- pressure drop
- fluent launcher
- mass flow ratio to overflow
- fluent 실행하는 방법
- air-core
- 하이드로사이클론
- 엑셀
- DPM
- 워드튠
- Today
- Total
공돌하우스
[딥러닝] Activation Function 소개 본문
안녕하세요 전자둥이입니다~
오늘은 여러가지 Activatoin Function에 대해서 소개해보겠습니다.
우선 Activation Function이 하는 역할에 대해서 알아보겠습니다. 딥러닝 모델을 설계를 하다보면 layer 사이사이에 activation function들이 있는 걸 확인 할 수 있습니다. 예를 한번 가져와보겠습니다.

resnet50의 일부를 가지고 와봤는데요. conv연산 사이사이에 ReLu라는 Activation Function이 있는 걸 확인 할 수 있습니다.
그럼 이제 왜 Activation Function 을 사용하는 가? 에대해서 설명 드리겠습니다.
아 그전에 혹시 학습이 어떤식으로 진행되는지 잘 모르시는 분들을 위해 정리가 잘 되어있는 유튜브 영상을 하나 가지고 와봤습니다. (Back propagation을 통한 weight value 업데이트 및 학습)
Activation Function 은 선형을 비선형으로 바꿔주는 역할도 하고 있습니다. 만약 Activation Function이 없어서 Linear한 값들로만 층을 쌓게되면 문제가 발생합니다. Linear한 함수들만 사용한 2-Layer 모델을 예를 들어보겠습니다.
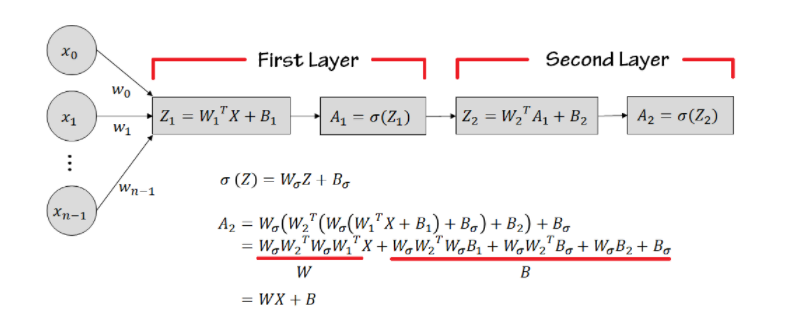
2개의 Layer을 쌓아봤지만 X에 곱해지는 항들은 W로 치환가능하고, 입력한 무관한 상수 전체는 B로 치환 가능하기 때문에 WX + B라는 Single Layer와 동일한 역할을 하게 됩니다. 따라서 비선형 함수는 Activation Function을 사이사이에 사용하게 됩니다.
Activation Function종류
(1) Sigmoid
앞서서 영상을 본 것처럼 weight value 는 backpropagation 을 통해 업데이트 되어집니다. 그러기위해서는 각 Value들이 미분이 되어야하는데 예전에는 step Function (계단 함수)를 사용해서 모델을 만들어서 backpropagation을 통해서 미분이 불가능 해졌습니다. 따라서 이를 미분가능한 value로 바꿔주는 함수가 Sigmoid함수 였습니다.

하지만 여기서 Sigmoid의 단점을 확인 할 수 있습니다. 바로 결과값이 무조건 0~1사이의 값을 가진다는 것인데요. 이렇게되면 깊은 층에 있는 weight value는 점차 작아지게 될것이고 0에 수렴하게 될것입니다. 그러면 최종적으로 weight Value을 업데이트 하지 못하는 문제가 발생하게됩니다. 이를 Vanishing Gradient라고 합니다.
(2)tanh
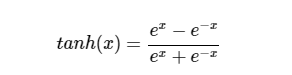

이는 Sigmoid 함수를 보완하기 위해 나온 함수입니다. 입력신호를 (-1, 1)사이의 값으로 normalization 해주는 효과가 있으며 거의 모든 방면에서 sigmoid보다 성능이 좋습니다. 하지만 sigmoid와 같이 Vanishing Gradient가 발생 할 수 있다는 단점이 있습니다.
(3) ReLU

ReLU는 함수에서 보면 아시다싶이 최대값이 정해져있지 않습니다. 따라서 Sigmoid, tanh의 단점인 Vanishing Gradient을 조금이나마 해결하기 위해 나온 Activation Function입니다. 게다가 exp함수를 사용하지 않아서 sigmoid함수보다 6배 정도 빠르게 학습됩니다. 하지만 여기에도 단점이 있습니다. 최소값이 0으로 정해져있다는 겁니다. 비선형으로 바꾸기 위해서 이러한 형태의 함수를 만들었다고 생각되어지지만 최소값이 0으로 정해져있다는 것은 아무래도 좋은 쪽으로는 작용하기 힘듭니다. 그래서 Dead Relu라는 표현을 쓰며 더이상 weight value가 업데이트 되지 않는 현상이 있습니다.
이를 보완하기 위해 나온 다양한 ReLU들이 있습니다. 그중에서 Leaky ReLU에 대해서 설명드리겠습니다.
(4) Leaky ReLU
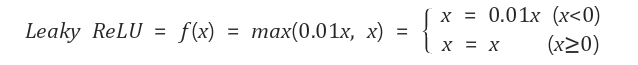
함수를 보시면 음수값도 적게나마 표현하기 위해 나온 Activation Function 입니다. ReLU보다는 Leaky ReLU를 사용하면 Dead ReLU를 피할 수 있다고 합니다.
(5) Swish

Swish는 매우 깊은 신경망에서 ReLU보다 높은 정확도를 달성한다고 합니다. 특징으로는 bounded below, unbounded above이 있습니다.
(6) mish

Mish는 그래프가 무한대로 뻗어나가며 Swish보다 조금 더 성능면에서 좋다고 합니다.
이상으로 Activation Function 들에 대해서 알아보았습니다. 감사합니다~
'AI' 카테고리의 다른 글
| [딥러닝]SSD모델 default anchor box 그려보기 (0) | 2021.09.03 |
|---|---|
| Distance-IOU Loss (0) | 2021.07.25 |
| 자연어 처리 중 wordnet (0) | 2021.06.20 |
| ResNet skip-connection (0) | 2021.05.30 |



