| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- python
- 행 삽입
- DPM
- 전산유체역학
- air-core
- 워드튠
- hydrocylcone
- fluent 실행하는 방법
- pdf annotation
- 업무노가다
- Excel
- pressure drop
- 자동화
- 업무자동화
- 구글시트
- Meshing
- regex
- 모니터링값
- 셀 배경색
- mass flow ratio to overflow
- 파이썬
- 후처리 프로그램
- fluent launcher
- CFD
- google sheet
- 업무
- 엑셀
- 유체역학
- 하이드로사이클론
- 정규표현식
- Today
- Total
공돌하우스
[정규표현식 활용] 텍스트 분리 예제 본문
안녕하세요! 빅톨입니다 :)
이번 포스팅에서는 구글 스프레드시트의 강력한 기능인 정규표현식(regexextract 함수)을 활용하는 예제를 보여드리겠습니다. 구글시트의 정규표현식 기능을 처음 접하신다면 [구글스프레드시트] 정규표현식 포스팅을 참고해주세요!
업무나 연구를 하다 보면 특정한 규칙에 의해서 결합된 문장 혹은 글들을 분리해야 하는 상황이 발생합니다. 예를 들어 선행연구 조사 리스트가 다음과 같은 형태로 정리되어 있다고 가정해 보겠습니다.

선행연구들이 "논문제목. [연도]. 저널이름." 의 규칙으로 정리되어 있는 것을 확인할 수 있습니다.
구글시트에서는 정규표현식을 활용하여 위 텍스트들을 간편하게 분리할 수 있습니다.
우선 위 규칙에 따라 논문제목, 연도, 저널이름을 추출하기 위한 정규표현식을 작성해야 합니다.
위 예제의 경우에는 ^(.*)\.\s\[(.*?)\]\.\s(.*?)\.$ <- 이렇게 작성하면 됩니다. 좀 더 직관적으로 확인해보기 위해 https://regexper.com/ 에서 도식화를 해보면 다음과 같습니다.

즉, 문장의 시작~첫번째 마침표 직전까지를 첫번째 그룹(논문제목)으로, 대괄호 사이를 두번째 그룹(연도)으로, 마지막으로 대괄호 뒤에 한칸 띄우고 나서부터 마침표까지를 세번째 그룹(저널이름)으로 추출하는 정규표현식입니다.
이제 https://regex101.com/ 에서 한번 테스트를 해보겠습니다.

위칸에 작성한 정규표현식을 넣고, 아래칸에 테스트하고자 하는 문구를 적으면 우측에 결과를 보여줍니다. 그룹1에 논문제목, 그룹2에 연도, 그룹3에 저널이름이 잘 추출된 것을 확인할 수 있습니다.
이제 구글 스프레드시트에 한번 적용해보겠습니다.
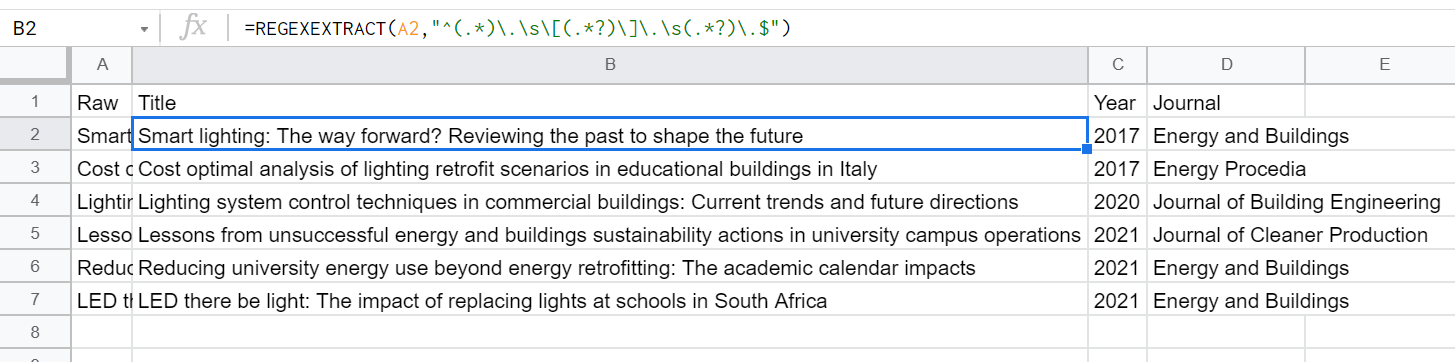
A열에 원본 텍스트가 있는 상황에서 B열에 =REGEXEXTRACT(분리할 문자열, "정규표현식")을 적어주면 B, C, D 열에 각 그룹이 분리되어 들어가게 됩니다.
정규표현식만 작성할 줄 안다면 정말 편리하게 해당 기능을 활용할 수 있습니다. 물론 정규표현식을 처음 익히는데 시간이 들긴 하지만 한번만 익혀두시면 훨씬 더 많은 시간을 절약할 수 있습니다.
다음에도 유용한 팁, 예제로 돌아오겠습니다!
감사합니다~
'구글 스프레드시트' 카테고리의 다른 글
| [구글스프레드시트] 메뉴 검색 단축키 (0) | 2021.08.22 |
|---|---|
| [구글스프레드시트] 셀범위 이름 정의 (0) | 2021.06.27 |
| [구글스프레드시트] 정규표현식 (0) | 2021.05.29 |